

Why breaking things should be practiced…
With the rise in microservices and serverless computing, applications have become more complex and distributed. Low latency and high availability made applications to be geo distributed and run in multiple replica sets. Multi node clusters across the globe with content distribution network have all added more complexity to applications. Increased complexity introduced more failures into the system which is very hard to locate using traditional means of testing. Point of failures are increasing exponentially, and it requires a different kind of approach to system resilience which assumes the system is too complex for humans to understand and predict what could fail in a production environment.
“Chaos Engineering is the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production.” — principlesofchaos.org
From the definition what we gather is that chaos engineering is a methodology to identify system faults by injecting problems intentionally to the production system in a controlled manner. The faults can be wide ranging, from latency, disk failure, network failure, node outage or even simulating outage from a cluster to an entire region. The need to identify weaknesses before they manifest into system-wide abnormal behaviors is of utmost importance to prevent major production downtime. The weaknesses could take the form of improper replica set when a service is unavailable; outages when a downstream service receives too much traffic; cascading failures when a single point of failure crashes. All these weaknesses need to be addressed proactively before it starts affecting customers in production. We need to manage the chaos inherent in these systems and have confidence in our production deployments despite the existing complexity that they represent.
History of Chaos Engineering
Chaos engineering became relevant with companies that were pioneering large scale distributed system. Due to high complexity of these systems, a new approach to test failure was necessary.
2010
The Netflix Engineering Tools team created Chaos Monkey. Chaos Monkey was created in response to Netflix’s move from physical infrastructure to cloud infrastructure provided by Amazon Web Services, and the need to be sure that a loss of an Amazon instance wouldn’t affect the Netflix streaming experience.
2011
The Simian Army was born. The Simian Army added additional failure injection modes on top of Chaos Monkey that would allow testing of a more complete suite of failure states, and thus build resilience to those as well. “The cloud is all about redundancy and fault-tolerance. Since no single component can guarantee 100% uptime (and even the most expensive hardware eventually fails), we have to design a cloud architecture where individual components can fail without affecting the availability of the entire system” — Netflix 2011
2012
Netflix shared the source code for Chaos Monkey on GitHub saying that they “have found that the best defense against major unexpected failures is to fail often. By frequently causing failures, we force our services to be built in a way that is more resilient” – Netflix 2012
2014
Netflix decided they would create a new role: The Chaos Engineer. Bruce Wong coined the term, and Dan Woods shared it with the greater engineering community via Twitter.
Chaos Engineering in Practice
To address uncertainty of distributed systems at scale, Chaos Engineering involves running thoughtful, planned experiments to uncover systemic weaknesses. These experiments follow four steps:
- Start by defining ‘steady state’ as some measurable output of a system that indicates normal behavior.
- Hypothesize that this steady state will continue in both the control group and the experimental group. Experimental group should be a small subset of the system considering that the injected failure would not disturb the customer experience.
- Introduce variables that reflect real world events like servers that crash, hard drives that malfunction, network connections that are severed, etc.
- Try to disprove the hypothesis by looking for a difference in steady state between the control group and the experimental group.
Minimize Blast Radius
Experimenting in production has the potential to cause unnecessary customer pain. While there must be an allowance for some short-term negative impact, it is the responsibility and obligation of the Chaos Engineer to ensure the fallout from experiments are minimized and contained.

Why Chaos Engineering is necessary – Why to break things on purpose?
It’s helpful to think of a vaccine or a flu shot where you inject yourself with a small amount of a potentially harmful foreign body in order to prevent illness. Chaos Engineering is a tool we use to build such an immunity in our technical systems by injecting harm (like latency, CPU failure, or network black holes) in order to find and mitigate potential weaknesses.
These experiments have the added benefit of helping teams build muscle memory in resolving outages, akin to a fire drill. By breaking things on purpose, we surface unknown issues that could impact our systems and customers.
It is very hard to predict where and how a failure can happen in a distributed system because they are inherently more complex than monolithic system. The “Eight Fallacies of Distributed Systems” shared by Peter Deutsch and others at Sun Microsystems describe false assumptions that programmers new to distributed applications invariably make.
Fallacies of Distributed System
- The network is reliable
- Latency is zero
- Bandwidth is infinite
- The network is secure
- Topology doesn’t change
- There is one administrator
- Transport cost is zero
- The network is homogeneous
Many of these fallacies drive the design of Chaos Engineering experiments such as “packet-loss attacks” and “latency attacks”. For example, network outages can cause a range of failures for applications that severely impact customers. Applications may stall while they wait endlessly for a packet. Applications may permanently consume memory or system resources. And even after a network outage has passed, applications may fail to retry stalled operations, or may retry too aggressively. Applications may even require a manual restart. Each of these examples need to be tested and prepared for.
How to start Chaos Engineering or what type of experiments to perform first
Experiments should be performed in a way which is more controlled and less disruptive, the following order if maintained can have more control over the experiments.
- Known Knowns – Things you are aware of and understand
- Known Unknowns – Things you are aware of but don’t fully understand
- Unknown Knowns – Things you understand but are not aware of
- Unknown Unknowns – Things you are neither aware of nor fully understand
The diagram below illustrates this concept in 2×2 matrix

In this example (as illustrated in gremlin web site), we have a cluster of 100 MySQL hosts with multiple shards per host.
In one region, we have a primary database host with two replicas, and we use semi-sync replication. We also have a pseudo primary and two pseudo replicas in a different region.
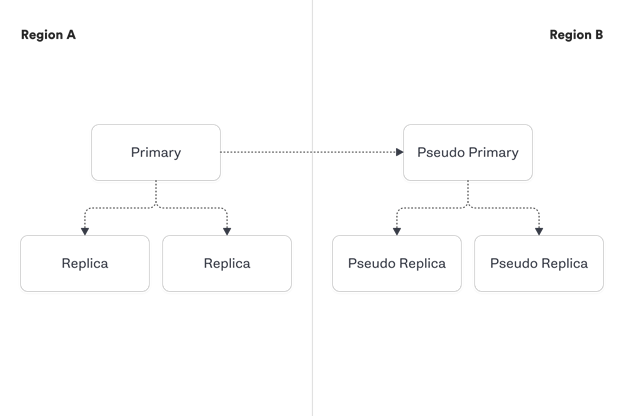
- Known-Knowns: We know that when a replica shuts down it will be removed from the cluster. We know that a new replica will then be cloned from the primary and added back to the cluster.
- Known-Unknowns: We know that the clone will occur, as we have logs that confirm if it succeeds or fails, but we don’t know the weekly average of the mean time it takes from experiencing a failure to adding a clone back to the cluster effectively.
- We know we will get an alert that the cluster has only one replica after 5 minutes, but we don’t know if our alerting threshold should be adjusted to more effectively prevent incidents.
- Unknown-Knowns: If we shutdown the two replicas for a cluster at the same time, we don’t know exactly the mean time during a Monday morning it would take us to clone two new replicas off the existing primary. But we do know we have a pseudo primary and two replicas which will also have the transactions.
- Unknown-Unknowns: We don’t know exactly what would happen if we shutdown an entire cluster in our main region, and we don’t know if the pseudo region would be able to failover effectively because we have not yet run this scenario.
We would create the following chaos experiments, working through them in order:
- Known-Knowns: shut down one replica and measure the time it takes for the shutdown to be detected, the replica to be removed, the clone to kick-off, the clone to be completed, and the clone to be added back to the cluster. Before you kick off this experiment increase replicas from two to three. Run the shutdown experiment at a regular frequency but aim to avoid the experiment resulting in 0 replicas at any time. Report on the mean total time to recovery for a replica shutdown failure and break this down by day and time to account for peak hours.
- Known-Unknowns: Use the results and data of the known-known experiment to answer questions which would currently be “known-unknowns”. You will now be able to know the impact the weekly average of the mean time it takes from experiencing a failure to adding a clone back to the cluster effectively. You will also know if 5 minutes is an appropriate alerting threshold to prevent SEVs.
- Unknown-Knowns: Increase the number of replicas to four before conducting this experiment. Shutdown two replicas for a cluster at the same time, collect the mean time during a Monday morning over several months to determine how long it would take us to clone two new replicas off the existing primary. This experiment may identify unknown issues, for example, the primary cannot handle the load from cloning and backups at the same time and you need to make better use of the replicas.
- Unknown-Unknowns: Shut down of an entire cluster (primary and two replicas) would require engineering work to make this possible. This failure may occur unexpectedly in the wild, but you are not yet ready to handle it. Prioritize the engineering work to handle this failure scenario before you perform chaos experiments.
Time To Fix The Injected Failure
After running our first experiment, hopefully, there is one of two outcomes: either we verified that our system is resilient to the failure you introduced, or we found a problem that needs to be fixed. Both are good outcomes. On one hand, we’ve increased our confidence in the system and its behavior, and on the other we found a problem before it caused an outage.
Chaos Engineering Tools
Here are few of the popular chaos tools used by different organizations:
- Chaos Monkey – A resiliency tool that helps applications tolerate random instance failures.
- orchestrator – MySQL replication topology management and HA.
- kube-monkey – An implementation of Netflix’s Chaos Monkey for Kubernetes clusters.
- Gremlin Inc. – Failure as a Service.
- Chaos Toolkit – A chaos engineering toolkit to help you build confidence in your software system.
- steadybit – A Chaos Engineering platform (SaaS or On-Prem) with auto discovery features, different attack types, user management and many more.
- PowerfulSeal – Adds chaos to your Kubernetes clusters, so that you can detect problems in your systems as early as possible. It kills targeted pods and takes VMs up and down.
- Wiremock – API mocking (Service Virtualization) which enables modeling real world faults and delays
- MockLab – API mocking (Service Virtualization) as a service which enables modeling real world faults and delays.
- Chaos Monkey for Spring Boot – Injects latencies, exceptions, and terminations into Spring Boot applications
- Byte-Monkey – Bytecode-level fault injection for the JVM. It works by instrumenting application code on the fly to deliberately introduce faults like exceptions and latency.
- GomJabbar – Chaos Monkey for your private cloud
- Turbulence – Tool focused on BOSH environments capable of stressing VMs, manipulating network traffic, and more. It is very similar to Gremlin.
- KubeInvaders – Gamified Chaos engineering tool for Kubernetes Clusters.
- VMware Mangle – Orchestrating Chaos Engineering.
- Litmus – Framework for Kubernetes environments that enables users to run test suites, capture logs, generate reports and perform chaos tests.
- Chaos-Mesh – Chaos Mesh is a cloud-native Chaos Engineering platform that orchestrates chaos on Kubernetes environments.
- Chaos HTTP Proxy – Introduce failures into HTTP requests via a proxy server
- Chaos Lemur – A self-hostable application to randomly destroy virtual machines in a BOSH-managed environment
- Simoorg – Linkedin’s very own failure inducer framework.
- react-chaos – A chaos engineering tool for your React apps.
Conclusion
As web systems have grown much more complex with the rise of distributed systems and microservices, system failures have become difficult to predict. So, in order to prevent failures from happening, we all need to be proactive in our efforts to learn from failure. Chaos Engineering is a powerful practice that is already changing how software is designed and engineered at some of the largest-scale operations in the world. Where other practices address velocity and flexibility, Chaos specifically tackles systemic uncertainty in these distributed systems. The Principles of Chaos provide confidence to innovate quickly at massive scales and give customers the high-quality experiences they deserve.
References
https://principlesofchaos.org/
http://wiki.c2.com/?DistributedComputing
https://github.com/dastergon/awesome-chaos-engineering
https://tanzu.vmware.com/content/blog/chaos-lemur-testing-high-availability-on-pivotal-cloud-foundry
https://tanzu.vmware.com/content/blog/pivotal-perspectives-unleash-the-chaos-lemur
https://codecentric.github.io/chaos-monkey-spring-boot/
https://codecentric.github.io/chaos-monkey-spring-boot/2.2.0/
Great coverage Manav.. Its fantastic !!!
Thanks Shibi!